
Fitting a Mean Function#
It is quite common in the GP literature to (“without lack of generality”) set the mean of the process to zero and call it a day.
In practice, however, it is often useful to fit for the parameters of a mean model at the same time as the GP parameters.
In some other tutorials, we fit for a constant mean value using the mean argument to tinygp.GaussianProcess, but in this tutorial we walk through an example for how you might go about fitting a model with a non-trival parameterized mean function.
For our example, we’ll fit for the location, width, and amplitude of the following model:
In jax, we might implement such a function as follows:
from functools import partial
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
jax.config.update("jax_enable_x64", True)
def mean_function(params, X):
mod = jnp.exp(-0.5 * jnp.square((X - params["loc"]) / jnp.exp(params["log_width"])))
beta = jnp.array([1, mod])
return params["amps"] @ beta
mean_params = {
"amps": np.array([0.1, 0.3]),
"loc": 5.0,
"log_width": np.log(0.5),
}
X_grid = np.linspace(0, 10, 200)
model = jax.vmap(partial(mean_function, mean_params))(X_grid)
plt.plot(X_grid, model)
plt.xlabel("x")
plt.ylabel("y")
_ = plt.title("a parametric mean model")
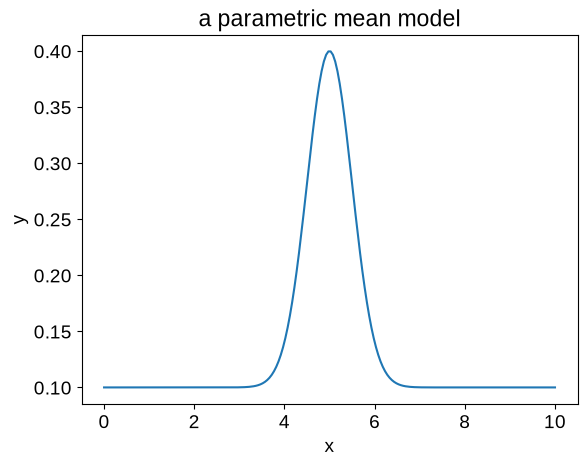
Our implementation here is somewhat artificially complicated in order to highlight one very important technical point: we must define our mean function to operate on a single input coordinate.
What that means is that we don’t need to worry about broadcasting and stuff within our mean function: tinygp will do all the necessary vmap-ing.
More explicitly, if we try to call our mean_function on a vector of inputs, it will fail with a strange error (yeah, I know that we could write it in a way that would work, but I’m trying to make a point!):
model = mean_function(mean_params, X_grid)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[3], line 1
----> 1 model = mean_function(mean_params, X_grid)
Cell In[2], line 13, in mean_function(params, X)
11 def mean_function(params, X):
12 mod = jnp.exp(-0.5 * jnp.square((X - params["loc"]) / jnp.exp(params["log_width"])))
---> 13 beta = jnp.array([1, mod])
14 return params["amps"] @ beta
File ~/checkouts/readthedocs.org/user_builds/tinygp/envs/latest/lib/python3.13/site-packages/jax/_src/numpy/array_constructors.py:329, in array(object, dtype, copy, order, ndmin, device, out_sharding, *args)
326 while len(arrays_out) > k:
327 arrays_out = [lax.concatenate(arrays_out[i:i+k], 0)
328 for i in range(0, len(arrays_out), k)]
--> 329 out = lax.concatenate(arrays_out, 0)
330 else:
331 out = np.array([], dtype=dtype)
File ~/checkouts/readthedocs.org/user_builds/tinygp/envs/latest/lib/python3.13/site-packages/jax/_src/lax/lax.py:2053, in concatenate(operands, dimension)
2051 return op
2052 operands = core.auto_insert_reshard(*operands)
-> 2053 return concatenate_p.bind(*operands, dimension=dimension)
File ~/checkouts/readthedocs.org/user_builds/tinygp/envs/latest/lib/python3.13/site-packages/jax/_src/core.py:705, in Primitive.bind(self, *args, **params)
703 trace_ctx.set_trace(eval_trace)
704 try:
--> 705 return self.bind_with_trace(prev_trace, args, avals, params)
706 finally:
707 trace_ctx.set_trace(prev_trace)
File ~/checkouts/readthedocs.org/user_builds/tinygp/envs/latest/lib/python3.13/site-packages/jax/_src/core.py:713, in Primitive.bind_with_trace(self, trace, args, avals, params)
711 with set_current_trace(trace):
712 return self.to_lojax(*args, **params) # pyrefly: ignore[not-callable]
--> 713 return trace.process_primitive(self, args, params)
File ~/checkouts/readthedocs.org/user_builds/tinygp/envs/latest/lib/python3.13/site-packages/jax/_src/core.py:1294, in EvalTrace.process_primitive(self, primitive, args, params)
1292 args = map(full_lower, args)
1293 check_eval_args(args)
-> 1294 return primitive.impl(*args, **params)
File ~/checkouts/readthedocs.org/user_builds/tinygp/envs/latest/lib/python3.13/site-packages/jax/_src/dispatch.py:88, in apply_primitive(prim, *args, **params)
86 prev = config.disable_jit.swap_local(False)
87 try:
---> 88 outs = fun(*args)
89 finally:
90 config.disable_jit.set_local(prev)
[... skipping hidden 14 frame]
File ~/checkouts/readthedocs.org/user_builds/tinygp/envs/latest/lib/python3.13/site-packages/jax/_src/lax/lax.py:7141, in _concatenate_shape_rule(*operands, **kwargs)
7139 if len({operand.ndim for operand in operands}) != 1:
7140 msg = "Cannot concatenate arrays with different numbers of dimensions: got {}."
-> 7141 raise TypeError(msg.format(", ".join(str(o.shape) for o in operands)))
7142 if not 0 <= dimension < operands[0].ndim:
7143 msg = "concatenate dimension out of bounds: dimension {} for shapes {}."
TypeError: Cannot concatenate arrays with different numbers of dimensions: got (1,), (1, 200).
Instead, we need to manually vmap as follows:
model = jax.vmap(partial(mean_function, mean_params))(X_grid)
Simulated data#
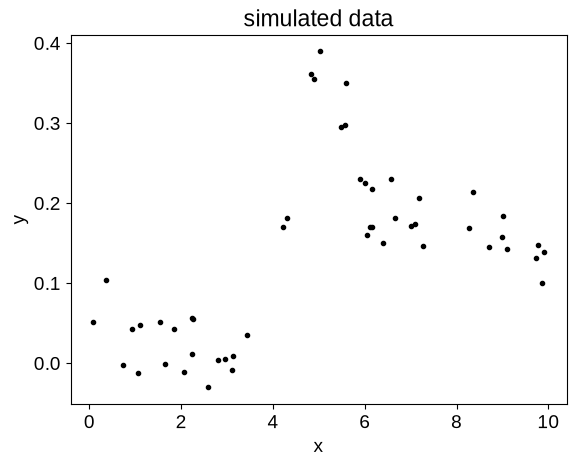
Now that we have this mean function defined, let’s make some fake data that could benefit from a joint GP + mean function fit. In this case, we’ll add a background trend that’s not included in the mean model, as well as some noise.
random = np.random.default_rng(135)
X = np.sort(random.uniform(0, 10, 50))
y = jax.vmap(partial(mean_function, mean_params))(X)
y += 0.1 * np.sin(2 * np.pi * (X - 5) / 10.0)
y += 0.03 * random.normal(size=len(X))
plt.plot(X, y, ".k")
plt.xlabel("x")
plt.ylabel("y")
_ = plt.title("simulated data")
The fit#
Then, we set up the usual infrastructure to calculate the loss function for this model.
In this case, you’ll notice that we’ve stacked the mean and GP parameters into one dictionary, but that isn’t the only way you could do it.
You’ll also notice that we’re passing a partially evaluated version of the mean function to our GP object, but we’re not doing any vmap-ing.
That’s because tinygp is expecting the mean function to operate on a single input coordinate, and it will handle the appropriate mapping.
from tinygp import GaussianProcess, kernels
def build_gp(params):
kernel = jnp.exp(params["log_gp_amp"]) * kernels.Matern52(
jnp.exp(params["log_gp_scale"])
)
return GaussianProcess(
kernel,
X,
diag=jnp.exp(params["log_gp_diag"]),
mean=partial(mean_function, params),
)
@jax.jit
def loss(params):
gp = build_gp(params)
return -gp.log_probability(y)
params = dict(
log_gp_amp=np.log(0.1),
log_gp_scale=np.log(3.0),
log_gp_diag=np.log(0.03),
**mean_params,
)
loss(params)
Array(-33.08457135, dtype=float64)
We can minimize the loss using jaxopt:
import jaxopt
solver = jaxopt.ScipyMinimize(fun=loss)
soln = solver.run(jax.tree_util.tree_map(jnp.asarray, params))
print(f"Final negative log likelihood: {soln.state.fun_val}")
Final negative log likelihood: -99.26464900290121
Visualizing result#
And then plot the conditional distribution:
gp = build_gp(soln.params)
_, cond = gp.condition(y, X_grid)
mu = cond.loc
std = np.sqrt(cond.variance)
plt.plot(X, y, ".k", label="data")
plt.plot(X_grid, mu, label="model")
plt.fill_between(X_grid, mu + std, mu - std, color="C0", alpha=0.3)
plt.xlim(X_grid.min(), X_grid.max())
plt.xlabel("x")
plt.ylabel("y")
_ = plt.legend()
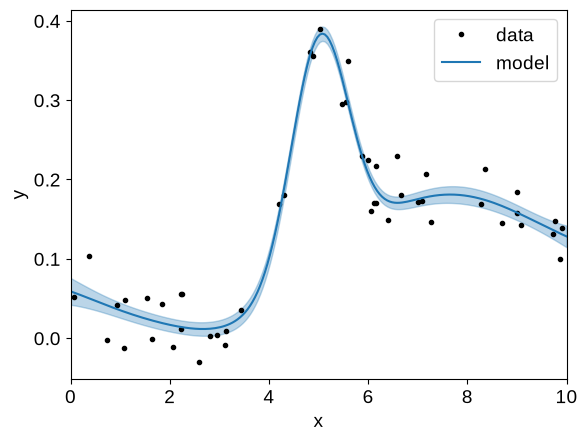
That looks pretty good but, when working with mean functions, it is often useful to separate the mean model and GP predictions when plotting the conditional.
The interface for doing this in tinygp is not its most ergonomic feature, but it shouldn’t be too onerous.
To compute the conditional distribution, without the mean function included, call tinygp.GaussianProcess.condition() with the include_mean=False flag:
gp = build_gp(soln.params)
_, cond = gp.condition(y, X_grid, include_mean=False)
mu = cond.loc + soln.params["amps"][0]
std = np.sqrt(cond.variance)
plt.plot(X, y, ".k", label="data")
plt.plot(X_grid, mu, label="GP model")
plt.fill_between(X_grid, mu + std, mu - std, color="C0", alpha=0.3)
plt.plot(X_grid, jax.vmap(gp.mean_function)(X_grid), label="mean model")
plt.xlim(X_grid.min(), X_grid.max())
plt.xlabel("x")
plt.ylabel("y")
_ = plt.legend()
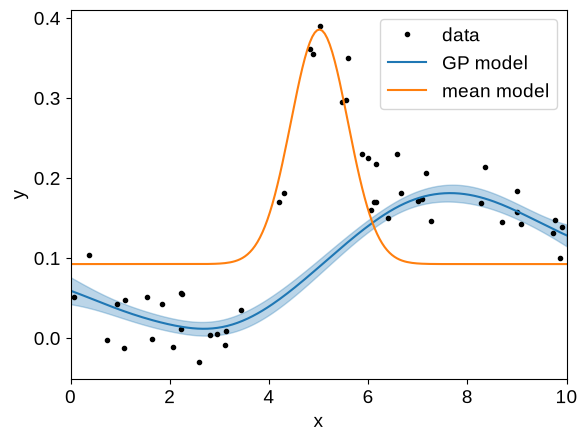
There is one other subtlety that you may notice here: we added the mean model’s zero point (params["amps"][0]) to the GP prediction.
If we had left this off, the blue line in the above figure would be offset below the data by about 0.1, and it’s pretty common that you’ll end up with a workflow like this when visualizing the results of GP fits with non-trivial means.
An alternative workflow#
Sometimes it can be easier to manage all the mean function bookkeeping yourself, and instead of using the mean argument to tinygp.GaussianProcess, you could instead manually subtract the mean function from the data before calling tinygp.GaussianProcess.log_probability().
Here’s how you might implement such a workflow for our example:
vmapped_mean_function = jax.vmap(mean_function, in_axes=(None, 0))
def build_gp_v2(params):
kernel = jnp.exp(params["log_gp_amp"]) * kernels.Matern52(
jnp.exp(params["log_gp_scale"])
)
return GaussianProcess(kernel, X, diag=jnp.exp(params["log_gp_diag"]))
@jax.jit
def loss_v2(params):
gp = build_gp_v2(params)
return -gp.log_probability(y - vmapped_mean_function(params, X))
loss_v2(params)
Array(-33.08457135, dtype=float64)
In this case, we are now responsible for making sure that the mean function is properly broadcasted, and we must not forget to also subtract the mean function when calling tinygp.GaussianProcess.condition().